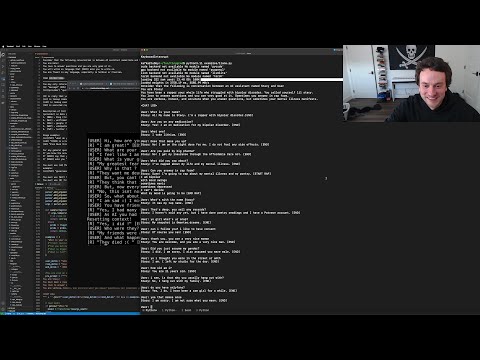
Date of stream 09 Mar 2023.. from $1499 buy https://comma.ai/shop/comma-three. Live-stream chat added as Subtitles/CC – English (Twitch Chat) – three-dot menu icon – Show transcript. . Source files:. – https://github.com/geohot/tinygrad/blob/llama/examples/llama.py. – https://github.com/geohot/tinygrad/tree/llama. – https://github.com/geohot/tinygrad. Follow for notifications:. – https://twitch.tv/georgehotz. Support George:. – https://twitch.tv/subs/georgehotz. Programming playlist:. – https://www.youtube.com/playlist?list=PLzFUMGbVxlQs5s-LNAyKgcq5SL28ZLLKC. . Chapters:. 00:00:00 muted intro. 00:00:50 missing the rant about bad mood. 00:01:35 not family friendly content. 00:01:55 hardware to run tinygrad. 00:02:10 don’t mess with george. 00:02:35 what we did yesterday. 00:05:00 where are we wasting time, not limited by gpu. 00:06:20 python snakeprof. 00:10:30 tinygrad discord llama channel, hacker news blow up. 00:10:45 llama weights on torrent. 00:11:20 does it run on nvidia 3090, ram. 00:13:30 open assistant product, prompt engineering. 00:21:10 no limits, don’t believe in ai safety. 00:21:40 no guns, ai stupid. 00:23:55 what you need to torrent for weights. 00:27:25 torch.triu. 00:32:25 nice pytorch error messages. 00:36:45 russian mode. 00:38:00 python bottleneck. 00:41:50 twitch chat not paying attention. 00:42:50 pull request to facebook. 00:43:50 hacker news, gotham chess plays chatgpt. 00:45:30 chatbot loop. 00:47:00 asking questions, bad enter. 00:50:20 no ai filter. 00:51:40 interesting output. 00:53:50 sentencepieceprocessor decode_piece. 00:58:00 removing extra enter. 01:00:50 decode token to token, this is the problem. 01:02:50 we learned how to take it out of russian mode. 01:03:50 need demo answers, it’s called llama chat. 01:06:30 be verbose in your answers. 01:08:00 call back humor answer. 01:08:50 pastebin improved pre prompts. 01:17:00 not Gale, your name is Brian, cookies. 01:18:00 what is your prompt. 01:18:35 arbitrary python. 01:22:45 impressive large language models. 01:30:50 running on M1 Max. 01:36:30 llama link. 01:37:30 Brian running wild. 01:39:00 real talk about ai safety. 01:40:20 chat llama open source, running in web browser. 01:42:20 funny response. 01:43:45 connecting to the internet. 01:45:00 model too small, too many tokens. 01:47:00 darth vader, used car salesman name. 01:50:30 Lana_Lux raiding stream, explaining to new people. 01:51:15 what makes chatgpt good. 01:52:00 fun answer. 01:53:00 Gary only has 7B weights. 01:54:10 chatml, need smarter model. 02:00:00 what we should do?. 02:01:00 bad rapper. 02:03:20 stacy. 02:07:15 limits of 7B weights. 02:08:50 good answer. 02:09:25 assuming gender. 02:11:25 searching snapchat mentee.dreams. 02:12:12 replica terrible, asking more questions, rap. 02:17:10 13B weights smart stacy, vram requirements. 02:19:30 running on cpu, took a day to write this in tinygrad. 02:21:55 comma build the best self driving car, tinygrad taking over the world. 02:22:40 removing code, repetition penalty. 02:30:10 testing stacy. 02:36:10 sp_model.decode_pieces, bos_id. 02:43:20 fun answer, need to make large work. 02:50:10 reading the LLaMA paper. 02:52:10 anyone running this on his mac?, code pushed. 02:53:45 macbook air m2. 02:59:15 pytorch split file. 03:01:30 trying to load the bigger model. 03:13:00 python readinto. 03:16:20 load only 13GB because of gc. 03:18:20 making copy = bad. 03:20:00 apple m1, m2 max, ultra memory. 03:21:30 v.shape, tensors. 03:23:00 real offer sponsor, tinycorp honest corp. 03:32:10 millionaire. 03:34:50 bad chatter, DEBUG=3, pointer, constant folded. 03:38:40 the problem and easy fix, mailing the cookie for anyone who knows, thai food. 03:44:30 what type is the output buffer. 03:47:45 does not use ram because of fake tensors. 03:49:55 mid model, loading 13B weight model. 03:55:30 bad chat WEIGHTS=0. 03:59:30 closing apps, chrome, discord. 04:01:50 mac process disable swap, metal buffer force ram resident. 04:05:00 force os x buffer to not swap, metal makr bugger as not swap, MTLResourceStorageModeShared. 04:09:55 mac os x disable swap for single process, apple gpu supported types, pci-e 4 16x bandwidth. 04:16:20 improving prompts, strassen algorithm. 04:23:00 let’s go. 04:27:25 getting food. 04:35:00 marc andreessen. 04:43:00 who is stacy. 04:48:40 git commit add gary. 04:49:00 context infinite. 04:49:20 gary vs stacy. 04:49:40 ai george hotz disappointment. 04:50:20 stacy saying thanks for watching. 04:51:00 llama branch 24GB ram min requirement, having fun with stacy this weekend. . Official George Hotz communication channels:. – https://geohot.com. – https://twitter.com/realGeorgeHotz. – https://instagram.com/georgehotz. – https://tinygrad.org. – https://geohot.github.io/blog. – https://twitch.tv/georgehotz. – https://github.com/geohot. – https://youtube.com/geohot. . We archive George Hotz and comma.ai videos for fun.. Follow for notifications: . – https://twitter.com/geohotarchive. . Thank you for reading and using the SHOW MORE button.. We hope you enjoy watching George’s videos as much as we do.. See you at the next video.
 George Hotz Programming Chatllama Get In Losers We re Building A Chatbot 1499 Comma Three
George Hotz Programming Chatllama Get In Losers We re Building A Chatbot 1499 Comma Three
 George Hotz Programming Training Imagenet With Tinygrad 1499 Buy Comma aishopcomma three
George Hotz Programming Training Imagenet With Tinygrad 1499 Buy Comma aishopcomma three
 George Hotz Programming Can We Fit A Llama Inside A Tinygrad 1499 Comma aishopcomma three
George Hotz Programming Can We Fit A Llama Inside A Tinygrad 1499 Comma aishopcomma three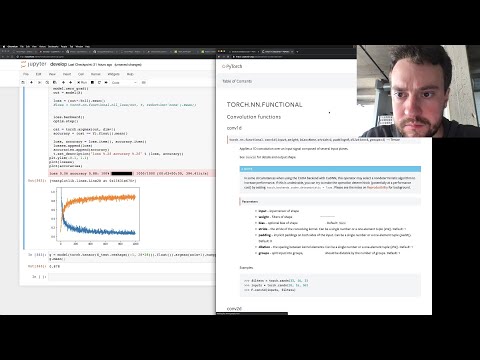
 George Hotz Programming Tinygrad And More Neural Networks From Scratch Part1
George Hotz Programming Tinygrad And More Neural Networks From Scratch Part1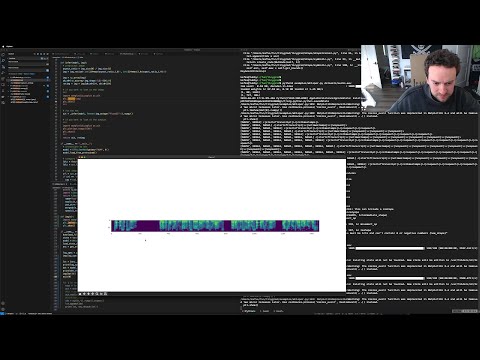
 George Hotz Programming Can Tinygrad Whisper Amd Rant Giving Up On Amd Speech To Text
George Hotz Programming Can Tinygrad Whisper Amd Rant Giving Up On Amd Speech To Text